Data pipelines
The covid19.ca.gov site team are a part of the last mile of data delivery. We rely on many stakeholders for review + verification, and data preparation. There is a lot of data preparation and ingestion that occurs upstream of the snowflake databases. We coordinate with other departments who feed data into snowflake, verify the SQL statements we use to retreive data and the publication schedules we should use to retrieve data already published to snowflake.
We keep a list of our data sources and the public facing displays they power in airtable
Manual approval done by our team
Some services are automated in how they pull data but open a pull request that awaits manual merging. Here’s an example with the tiers update.
Data udpates approved by other departments
The equity dashboard requires manual review of the scheduled data updates.
This is supervised by Dr Jason Vargo and his team from CDPH.
We create a historical record of their review by following these steps:
- The data is retrieved from snowflake on schedule and published to a staging location. The service for the equity dashboard is here
- charts in our staging environment consume latest data from the staging location
- a git pull request is opened by our automatic service that notifies Dr Vargo of the new data, provides a link to the staging site to review the update using live chart code
- if the data is problematic issues are recorded in the git pull request log
- if the dats is fine approvals are recorded in the git pull request log
- The CDPH team presses merge on the pull request triggering the live data publication
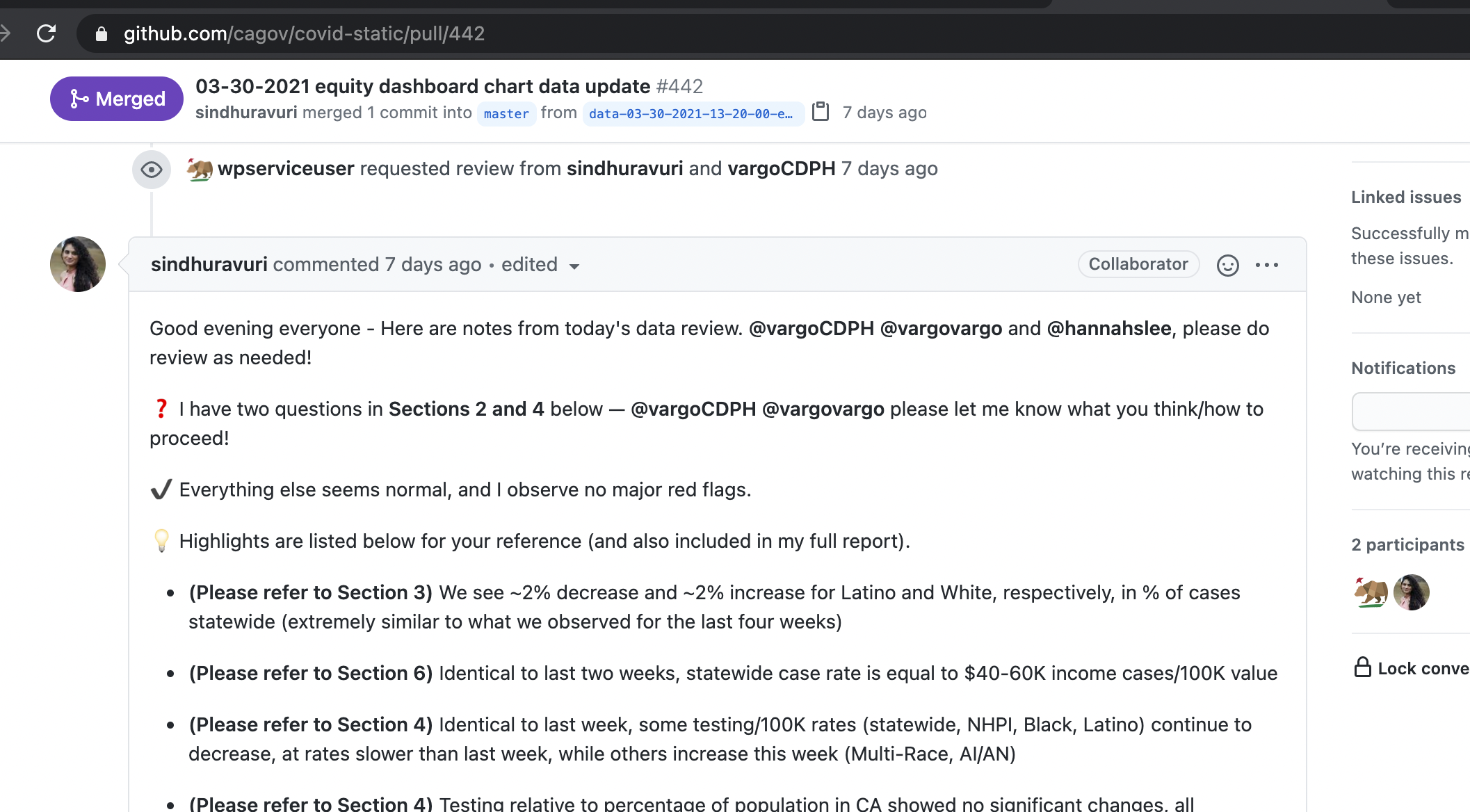
from: equity dash pull request
The Snowflake SQL statements to retreive data are separated from the code which executes them and viewable here.